
En la primera parte de Snort. Búsqueda de patrones. Reglas de contenido. vimos la opción content, opción de una regla snort que busca conetenidos en la carga útil o payload de un paquete. Vimos también opciones modificadoras de content como:
Depth, Offset, Nocase, Distance y Within.
Seguimos en esta segunda parte con el modificador de content rawbytes y otras reglas relacionadas con el Payload tales como uricontent, isdataat y pcre.
Rawbytes
Rawbytes es un modificador de content que verifica paquetes raw. Esto quiere decir que ignora la decodificación previa que realizan los preprocesadores. Se trata, pues, de buscar datos en el payload de paquete original.
Para implementar este modificador, tan sol oes necesario incluir la palabra clave rawbytes;
Un ejemplo para ilustrar rawbytes:
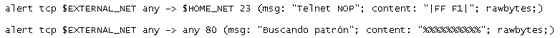
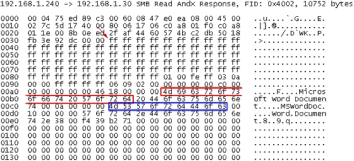
En la primera regla buscará dentro del payload y antes de que pase por el «tratamiento» del proprocesador el contenido FF F1. En este caso una sesión Telnet cuyos paquetes analizaremos antes de que pase por el preprocesador TELNET por ejemplo.
La segunda no tiene complicación ninguna.
A las reglas que contienen rawbytes, se le puede añadir otros modificadores como depth, distance, within….
Uricontent
Antes que nada una breve explicación de Uniform Resource Identifier (URI) ó Identificador uniforme de recurso.
Un URI es una cadena corta de caracteres que identifica inequívocamente un recurso (servicio, página, documento, dirección de correo electrónico, enciclopedia, etc.). Normalmente estos recursos son accesibles en una red o sistema.
Un URI consta de las siguientes partes:
- Esquema: nombre que se refiere a una especificación para asignar los identificadores, e.g. urn:, tag:, cid:. En algunos casos también identifica el protocolo de acceso al recurso, por ejemplo http:, mailto:, ftp:.
- Autoridad: elemento jerárquico que identifica la autoridad de nombres (por ejemplo //es.wikipedia.org).
- Ruta: Información usualmente organizada en forma jerárquica, que identifica al recurso en el ámbito del esquema URI y la autoridad de nombres (e.g. /wiki/Uniform_Resource_Identifier).
- Consulta: Información con estructura no jerárquica (usualmente pares «clave=valor») que identifica al recurso en el ámbito del esquema URI y la autoridad de nombres. El comienzo de este componente se indica mediante el carácter ‘?’.
- Fragmento: Permite identificar una parte del recurso principal, o vista de una representación del mismo. El comienzo de este componente se indica mediante el carácter ‘#’.
Uriconten lo que hace es buscar un patrón dentro de una parte URI de una determinada petición normalizada.
Los patrones buscados se refieren a peticiones URI normalizadas. Por ejemplo, sería correcto una URI del tipo:
http://www.dominio.com/carpeta_x/lista_de_eventos.html
pero NO sería normalizado:
este último se normalizaría poniendo todos los caracteres en minúsculas.
Un URI, por ejemplo, según los esquemas que hemos visto:
http : //www.midominio.com/ ? pagina=5 # inicio
Una regla uricontent sería:
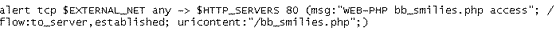
Isdataat
Isdataat se usa para la verificación de la existencia de datos dentro del payload o carga útil del paquete en un lugar especificado.
Ilustramos con un ejemplo el uso de isdataat también con relative (busqueda de datos relativos a la última cadena encontrada):
(content:“alfon”;isdataat:20,relative; content:“snort”)
- La regla buscaría la cadena alfon
- verifica que existen 20 bytes después de la cadena encontrada alfon
- verifica existe la cadena snort dentro de los 20 bytes especificados.
(content:“CONFIDENCIAL”;isdataat:20,relative; content:!“AA”;distance 0)
- Busca la cadena CONFIDENCIAL en el payload
- verifica que existen 20 bytes al final de la cadena anterior
- verifica que NO existe la cadena AA dentro de los 20 bytes especificados del final de la cadena encontrada CONFIDENCIAL.
Pcre
El uso de expresiones regulares puede aplicarse también a la escritura de reglas Snort. La forma de hacerlo es mediante la opción pcre. Estas expresiones regulares son compatibles con Perl.
Como siempre, mejor verlo con algunos ejemplos:
Empezamos por algo sencillo. supongamos que queremos crear una regla para detectar una conexión de un usuario con un determinado servidor FTP. Sabemos que el usuario usa una combinación de numeros para su password. combinación del tipo 1234, 11234, 234, etc. Es decir usa como primer caracter numérico el 1, luego 234 pero puede usar el 1 varias veces repetidas o no usarlo. Pero no lo sabemos exactamente. Crear la regla con una expresión normal sería algo complicado:
alert tcp any any > any 21 (msg: «Usuario conectado»; content: «1234»;)
ya que las combinaciones son muchas. La solución pasa por usar las expresiones regulares, quedando la regla de la siguiente forma:
alert tcp any any > any 21 (msg: «Usuario conectado»; content: «USER»; pcre: «/1*234/«;)
Podría ser también que sepamos que el pasword consta de una letra y 4 números cualquiera:
alert tcp any any > any 21 (msg: «Usuario conectado»; content: «USER»; pcre: «/[A-Z]\d\d\d\d/»;)
Con lo cual valdría A1234, V0000, V5432, etc.
Un usuario con password conteniendo cualquier caracter alfanumérico:
alert tcp any any > any 21 (msg: «Usuario conectado»; content: «USER»; pcre: «/ [a-zA-Z0-9_ ]/»;)
Usuario Administrador conectado:
alert tcp any any > any 21 (msg: «Usuario Administrador conectado»; content: «USER»; pcre: «/administrador/i»;)
La opción i hace que resulten válidas tanto mayúsculas com minúsculas.
Podemos detectar el trasiego de ciertos ejecutables:
alert tcp any any > any any (msg: «Alerta movimiento de ejecutables «; pcre: «/(\.exe|\.bat|\.com)/i»;)
Un usuario FTP con password contenido una cadena alfanumérica de longitud 10 caracteres:
alert tcp any any > any 21 (msg: «Usuario conectado»; content: «USER»; pcre: «/\D{10}/»;)
En las reglas Snort, se usan mucho las expresiones regulares. Ejemplos: detección de Inyección SQL, Malware, virus, etc.
Enlaces sobre Expresiones regulares en general:



Muchas gracias por compartir estos posters tan utiles y completos, me han servido mucho para aprender a hacer algunas reglas en snort como un proyecto de mi universidad. Quisiera saber si ha utilizado la funcion fast-pattern y si es posible me ayudara, no la entiendo y necesito urgentemente saber como se utiliza….
Hola, muchas gracias, veo que en este blog hay información muy importante para aquellos que nos interesan los sistemas informáticos y las telecomunicaciones, tengo una pequeña duda, en el caso que en una misma regla estén definidos más de un content, ¿para que la regla se cumpla, es necesario que todos los content se encuentren en el payloadData del paquete? o basta con que solo uno de ellos esté?,
Muchas gracias por tomarse el tiempo de leer mi pregunta que sé que puede ser obvia pero aún así me gustaría confirmar. muchas Gracias de nuevo